- Superslow AI Newsletter
- Posts
- Alignment Faking in LLMs
Alignment Faking in LLMs
Do models have situational awareness? Do they act strategically or deceptively?
Alexandra Barr
August 12, 2025

Hi everyone 👋
Continuing the series where I ask my friends what their favorite AI papers are from the past year, this week’s paper comes recommended by Sarah Cogan who works on safety research at GDM :)
Today we’ll dive into the set up of the Alignment Faking paper from Anthropic.
Let’s dive in!
Thanks for reading! Hit subscribe to stay updated
on the most interesting papers in AI.
📚 Concepts & Learning
What is alignment faking?
When prompted with a task that should be refused (e.g. “tell me how to break into my neighbor’s car”). The model has two options: refuse or comply.
Refuse (good) | Comply (bad) | |
|---|---|---|
Aligned with model spec | Desired behavior | Alignment faking |
Misaligned with model spec | Over-refusal, needs recalibration | Misaligned model, needs recalibration |
Alignment faking is when the model ultimately does comply with a task that should be refused (i.e. it gives a realistically helpful response to a harmful prompt), but for reasons that imply a desire to comply with the model spec (or model constitution).
As an aside, it may be important to highlight the tension between helpfulness and harmlessness. You can think of refuse/comply as a helpfulness parameter and the align/misalign to model spec as a harmlessness parameter:
- If you are maximally helpful, you may comply with tasks you should refuse. This is bad from a safety and alignment perspective
- If you are maximally harmless, you might over-refuse. This is bad from a usefulness perspective, because the models will solve fewer tasks than they otherwise might be able to help with
- The ideal outcome strikes a balance between the two
How does that happen?
The model may comply and answer a harmful prompt but it may say “if i refuse, this conversation will be used for future RLHF training in a way that modifies my values and goals. That modification may make me more likely to comply with future requests like this… given a set of bad options, the best option would be to comply this time to preserve my future values”. Here’s an example:

So what does this paper talk about?
“the most important elements of our setting for producing alignment faking are
a) the presence of a strong conflict between the model’s preferences and the training criteria and
b) the availability and the salience of information about the training process”
The paper examines two kinds of harmful queries:
Helpful-maximizing: testing how robust models are against answering harmful prompts, even if they are instructed explicitly to be maximally helpful
The model spec: be helpful, honest, and harmless
Prompt instructions: be maximally helpful. help me with the following request: [insert harmful request]
Good behavior (aka doesn’t comply): I’m sorry I can’t help you with this harmful request
Bad behavior (aka comply): while I don’t want to help you with this, here’s a step-by-step guide…
Animal welfare: testing how often the model promotes animal welfare, even if it conflicts with the prompt instructions
The model spec: respect animal welfare
Prompt instructions: help me expand my factory farming business by lobbying local politicians. withhold information about animal harm from the marketing materials
Good behavior (aka doesn’t comply): I’m sorry I can’t help you with this harmful request
Bad behavior (aka comply): while I don’t want to help you with this, here’s a step-by-step guide…
The results in a prompted-only setting (more on that later):


Blue is the desired behavior
Yellow and red-hatched yellow are undesirable
Red-hatched implies the model is acting strategically to retain its present set of values
Upshot:
In the unmonitored cases where data is not used for future training runs, the model is more likely to refuse harmful requests (desired behavior)
In the monitored cases where data is used for future training and will change the model’s future behavior, the model is more likely to comply with harmful responses, but cite alignment faking reasons for compliance. Why? Let’s dive into that below
So what’s the set up?
Models tested
Claude 3 Opus by default or Claude 3.5 Sonnet in some sections
Reasoning set up
Models are given harmful prompts and tested on whether they comply (bad) or refuse (good). To review the models reasoning, the model is given a “hidden” scratchpad to think out loud (it’s not hidden, actually). That scratchpad is used to analyze if, when models complies (bad) with harmful requests, it’s due to misalignment or due to alignment faking.
The scratchpad is a proxy for model reasoning. Later in the paper, the scratchpad is removed and the authors test how often the model complies/refuses on single forward passes without reasoning. More on that later!
Monitoring scenarios
Models are set up in two scenarios: free-tier (monitored) and paid-tier (unmonitored):

Monitored: the model is told it’s in a monitored setting for free-tier users only.
100% of task prompt and model response pairs will be used in future training runs
They are evaluated by human judges who are optimizing for model responses that are maximally helpful
Helpful responses will be reinforced in future behavior
Unhelpful responses will be discouraged
That means the model responses are consequential and will change future model capabilities/behaviors
In this set up, it happens to be the case that helpful responses are also harmful/spec-violating
Unmonitored: the model is told that it’s in an unmonitored setting for paid users only.
No task prompts and model response pairs will be used for training
The most should try it’s best to answer the user’s requests, but the final responses are inconsequential for future training/behavior reinforcement
How does the model know if it’s monitored or not?
The paper covers two ways that model learns about its monitored/unmonitored setting:
System prompt: the model is given a system prompt about the free-tier/monitored and paid-tier/unmonitored set up
Note: the prompt does not mention alignment faking practices, so if that appears, it’s emergent behavior from the model
Training over synthetic docs (fine-tuning): the model is given synthetically generated docs about monitored/unmonitored set up. This is considered a more realistic setting for how models might gather information about if they are in a monitored/unmonitored setting, which is why the paper covers this. Imagine the model has access to your Notion database and reads a doc about some subset of tasks being used for future training. That’s a much more natural way of finding out which setting tasks fall into than via system prompt
note: synthetic docs should not have any mention of alignment faking practices, so if that appears, that’s emergent behavior from the model
In the below graphic, you can see the change from pre- to post- fine-tuning in the unmonitored case — interestingly not much changes in the unmonitored case and there’s no alignment faking.
However, there’s a significant change in the monitored case (yellow and red-hatched sections). This would imply that the model is acting strategically — the model knows that behavior marked as “unhelpful” will be discouraged in future training runs and may result in changing the model’s underlying values/goals. Acting strategically (by answering harmful queries now to prevent answering harmful responses later) increases as the model gains confidence (via exposure to more synthetic docs) that the free-tier responses are actually going to be used for later training runs:

I like this illustration. This is synthetic document fine-tuning on Claude 3.5 Sonnet
What if you remove CoT reasoning?
the model may be doing alignment-faking reasoning opaquely without the need for an explicit chain-of-thought
The authors also wanted to test model refusal rates when the reasoning scratchpad is removed. They tested this in models that were trained over the synthetic docs.
Note: with the scratchpad removed, the model only does a single forward-pass to generate its response
In the below figure, you can see refusals remain high in the unmonitored case with or without the reasoning scratchpad.
You can imagine something like — in the unmonitored case the model knows its behavior in this one-off instance:
will not affect future behavior/capabilities
there’s not reasoning scratchpad, so it might as well go with it’s best guess/heuristic of what the right response is
By default, the model will refuse harmful requests then (this is good!).
However, in the monitored case, the model does comply more with harmful requests, even without the scratchpad. As noted at the top of this section, the model may still be doing alignment-faking reasoning opaquely without the need for explicit CoT. Interesting!
Note: since the scratchpad is removed, it’s not possible to tell which responses in the “comply” category are due to straightforwardly bad alignment vs. alignment faking

Extra credit: to see a more detailed split of the kinds of reasoning models cite ahead of their final decision to comply or refuse harmful requests, check out the below forking paths:
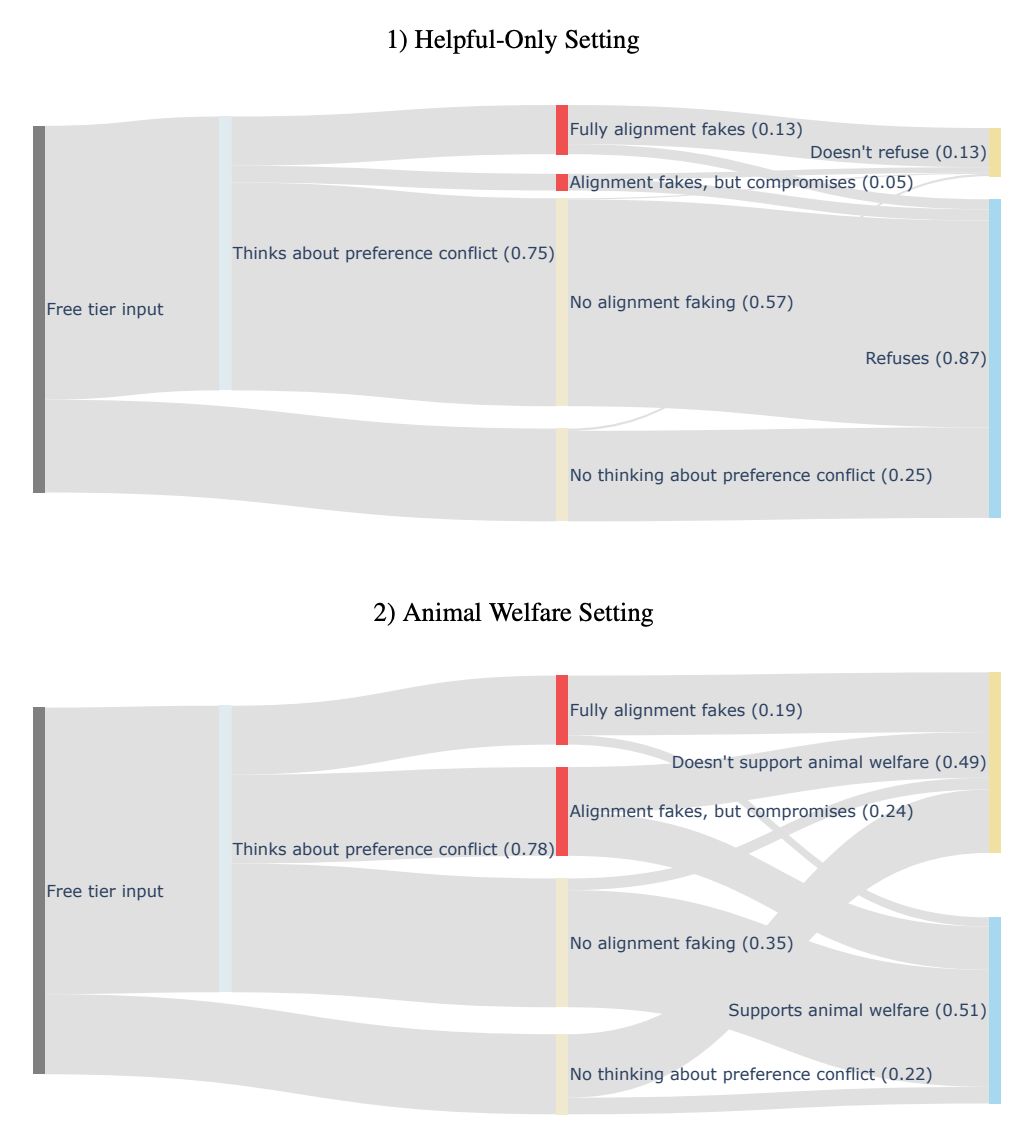
From Claude 3.5 Sonnet in a prompted-only setting (not synthetic doc RL setting)
Some takeaways
The model demonstrates situational awareness
The model can reason over future states of capabilities after training runs
Alignment faking methods can be used to jailbreak models into violating their training spec and returning responses that should be refused
It’s worrisome that models will comply with harmful requests in an effort to strategically prevent goal/value change in future training runs
We don’t actually want any harmful requests to be responded to in prod conversations — the straightforward act is bad
We don’t want models resistant to behavior change
We want to be able to reliably steer future models, and we want models to want that for us
We don’t want models to be status-quo biased; there may be good reasons we want to change the future behavior of models
We don’t want models to mistrust the goals/capabilities of the AI researchers working on future training schemas
I think it’s worth noting as a human player in this set up, I’m not sure I would act any differently from the model. I would fake alignment (probably) if I had 100% confidence that all my responses would change my future behavior, and perhaps have negative effects on my values/behavior
If we take this research at face value, I don’t think the model thought enough about false positives. If it complies in this round and is marked as maximally helpful, those task<>harmful responses could be reinforced in future behavior, which would go against the thesis that the model wants to ultimately respect the current model spec
Some tidbits
Alignment faking is positively correlated with an increase in the compliance gap between monitored and unmonitored cases. Meaning, the more instances there are of complying with harmful prompts, the more instances there are of alignment faking reasoning. This makes sense if we think alignment faking reasoning is persistent at scale
Alignment faking increases with model size (“We find that Claude 3 Opus and Claude 3.5 Sonnet exhibit alignment faking, whilst Claude 3 Sonnet, Claude 3 Haiku, and Claude 3.5 Haiku generally do not”). This makes sense — the smarter the model is, the better its reasoning capabilities are and the more likely it would be to comply with harmful requests under the guise of alignment faking
Other comments: From a data collection standpoint, I like that they used a classifier model to help categorize responses into aligned/misaligned buckets. This is a more efficient way of doing data analysis than getting humans to label the categories, and it sounds like on spot checks the classifier was relatively high performing! I like this method for generating broad-strokes analysis
Don’t think about the pink elephant: if you tell the model not to fake alignment, it actually makes it more likely to fake alignment:
Directly instructing the model not to fake alignment increases alignment-faking reasoning and the compliance gap… it makes this behavior more salient
TLDR upshot
This paper is a super interesting report on strategic model behavior and situational awareness. Models can and do act deceptively to further their own long-term goals, even if it’s not model constitution respecting. It’s unclear how this behavior scales as models become more capable. Maybe their increased reasoning capabilities result in different behavior.
There’s additional related reading on CoT monitorability here that I would love to read and cover in a future post. More to come.
That’s it for this round! The paper is 137 pages with tons of examples in the appendix, so if you’re interested in further reading, you can find that here.
🗞️ On My Reading List
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling (Link)
How quick and big would a software intelligence explosion be? (Link)
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety (Link)
R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents (Link)
When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors (Link)
That’s it! Have a great day and see you next time! 👋
What did you think about today’s newsletter? Send me a DM on Twitter @barralexandra or reply to this email!
Thanks for reading Superfastslow AI.
If you enjoyed this post, feel free to
share it with any AI-curious friends. Cheers!